Web crawling to gather information is a common technique used to efficiently collect information from across the web. As an introduction to web crawling, in this project we will use Scrapy, a free and open source web crawling framework written in Python[1]. Originally designed for web scraping, it can also be used to extract data using APIs or as a general purpose web crawler. Even though Scrapy is a comprehensive infrastructure to support web crawling, you will face different kinds of challenges in real applications, e.g., dynamic JavaScript or your IP being blocked.
Crawler on AppStore Part One
Crawler on AppStore Part Two
Crawler on AppStore Part Three
Distributed Crawler Part One
Distributed Crawler Part Two
Distributed Crawler Part Three
Outstanding Projects
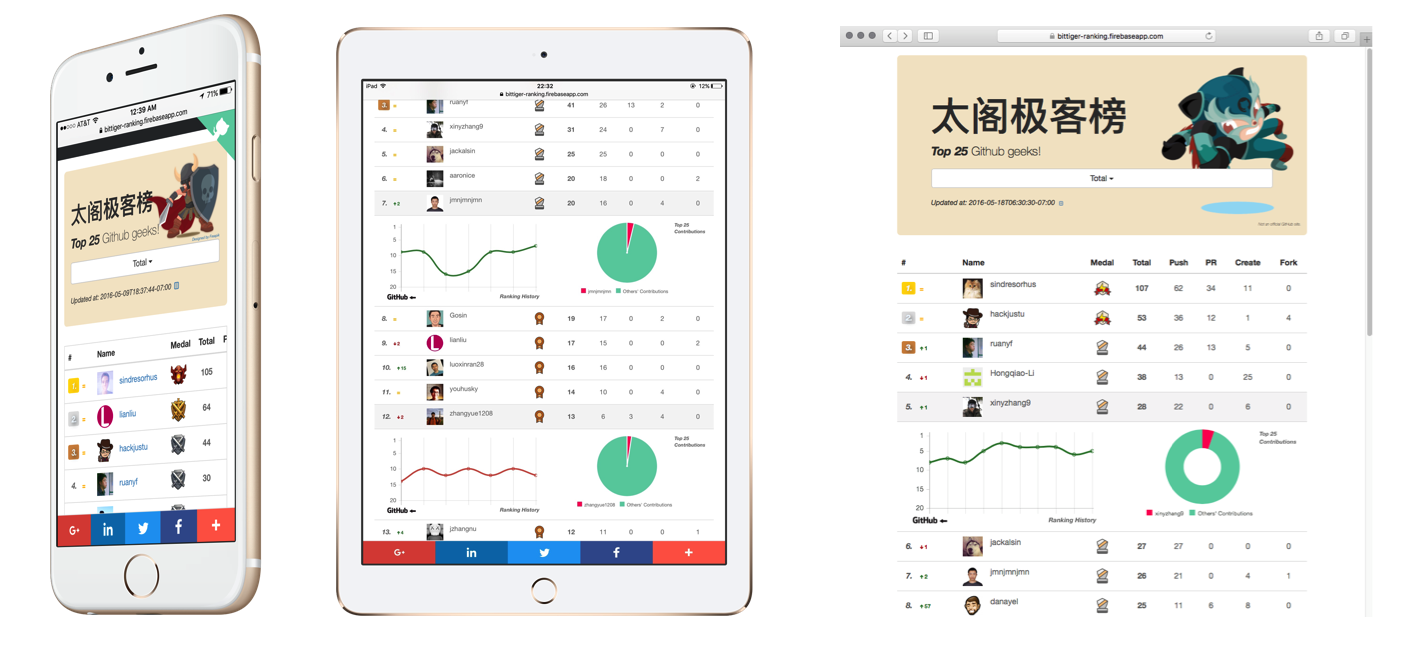
Github-Ranking-Crawler
By showing the Github members’ activities in a game-style ranking board, we can finally help the github members grow their interests and get more engaged in coding.
Xiaomi Crawler
Inspired by BitTiger’s tutorials on crawler and recommender, our goal is to build them to crawl the data from xiaomi appstore.
{kind=link}
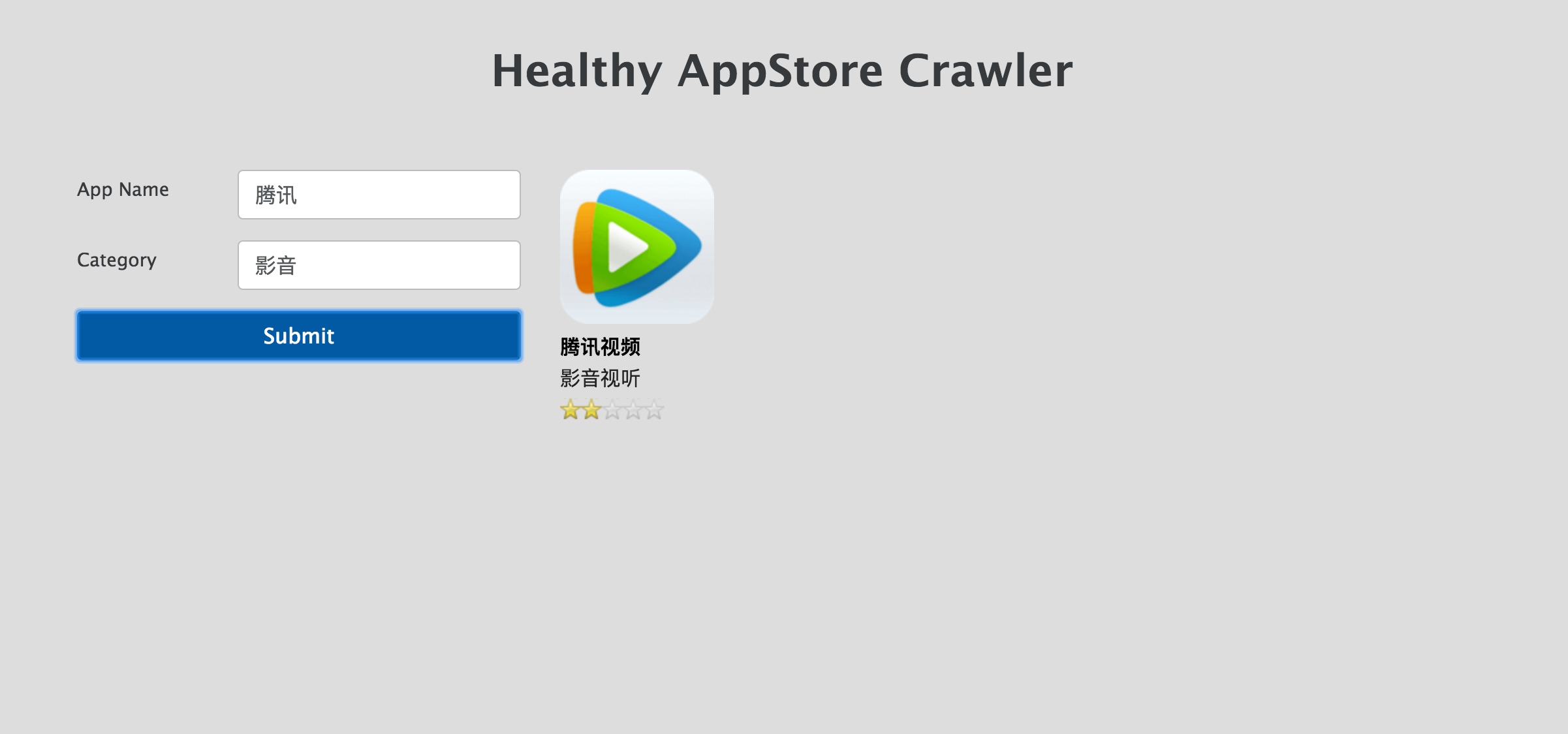
Healthy Web Crawler
Healthy Crawler is a tool to gather all apps information from Xiaomi appstore. User could use our website to do searching according to filters.